一,总体架构
haystack通过减小文件元数据的大小,使得所有文件的元数据都存在于内存中,保证每次读写图片最多一次I/O, 从而降低了访问的延时。没有haystack的时候,需要降低延时,则要利用到CDN, 而社交网络中图片访问的热点效应并不明显,因此CDN需要缓存的数据量巨大,成本很高。
haystack由三个组件构成:
- haystack directory
- haystack cache
- haystack store
haystack store用于存放图片数据,将多组物理卷(physical volume,应该是以硬盘为单位)组织为逻辑卷(logical volume); haystack cache用于缓存; haystack directory是整个系统的元数据管理服务器, 用于:
- 存放数据路由信息
- 负载均衡管理
- 缓存策略控制
- 容灾管理
二,读写流程
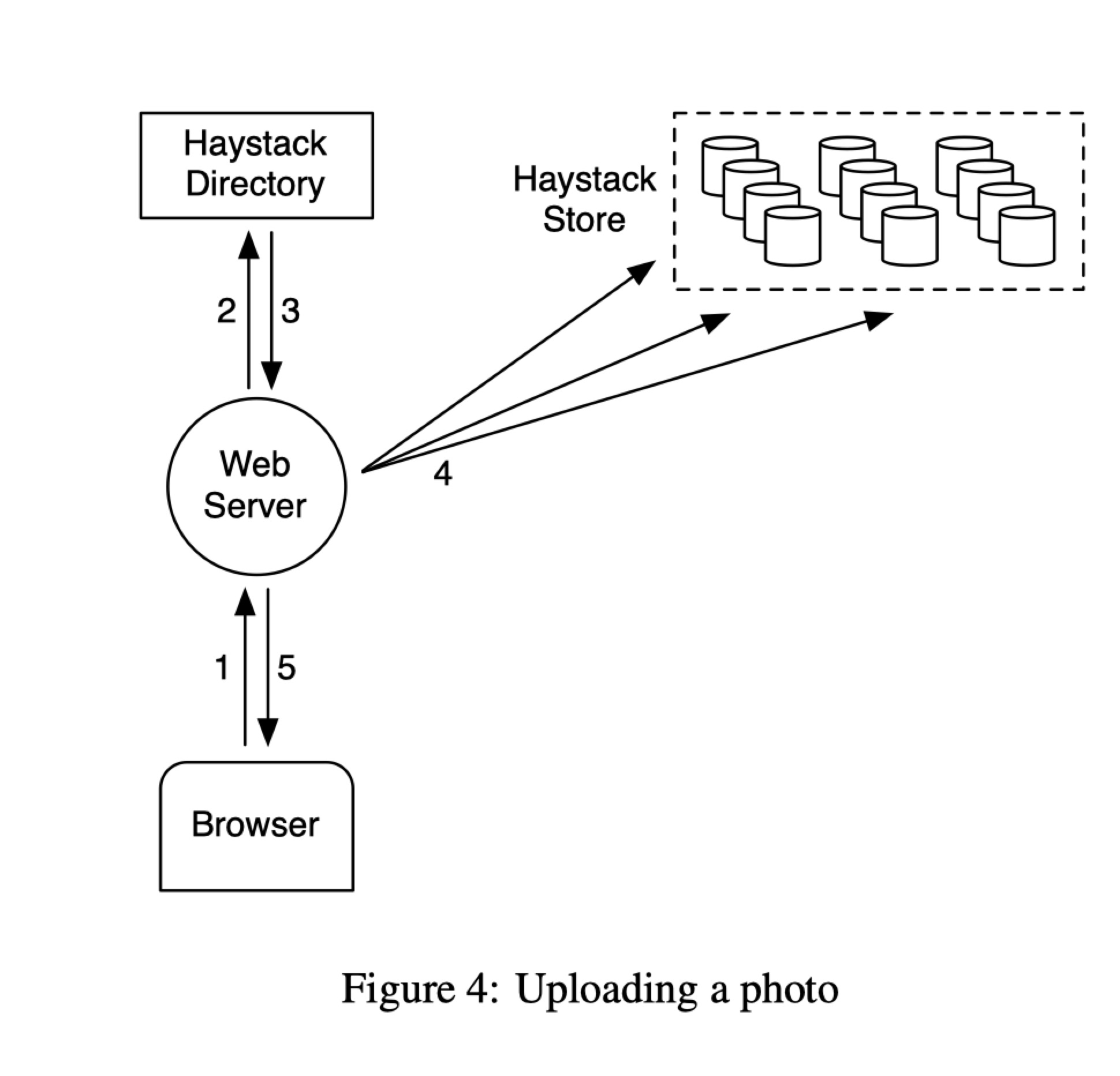
写流程(参考Figure 4), 用户通过web server上传图片,web server联系haystack directory, haystack directory告诉web server图片应该放到哪个逻辑卷,web server为这个图片生成一个唯一ID, 把该图片上传到指定逻辑卷中的所有物理卷中(多副本用于容灾)。
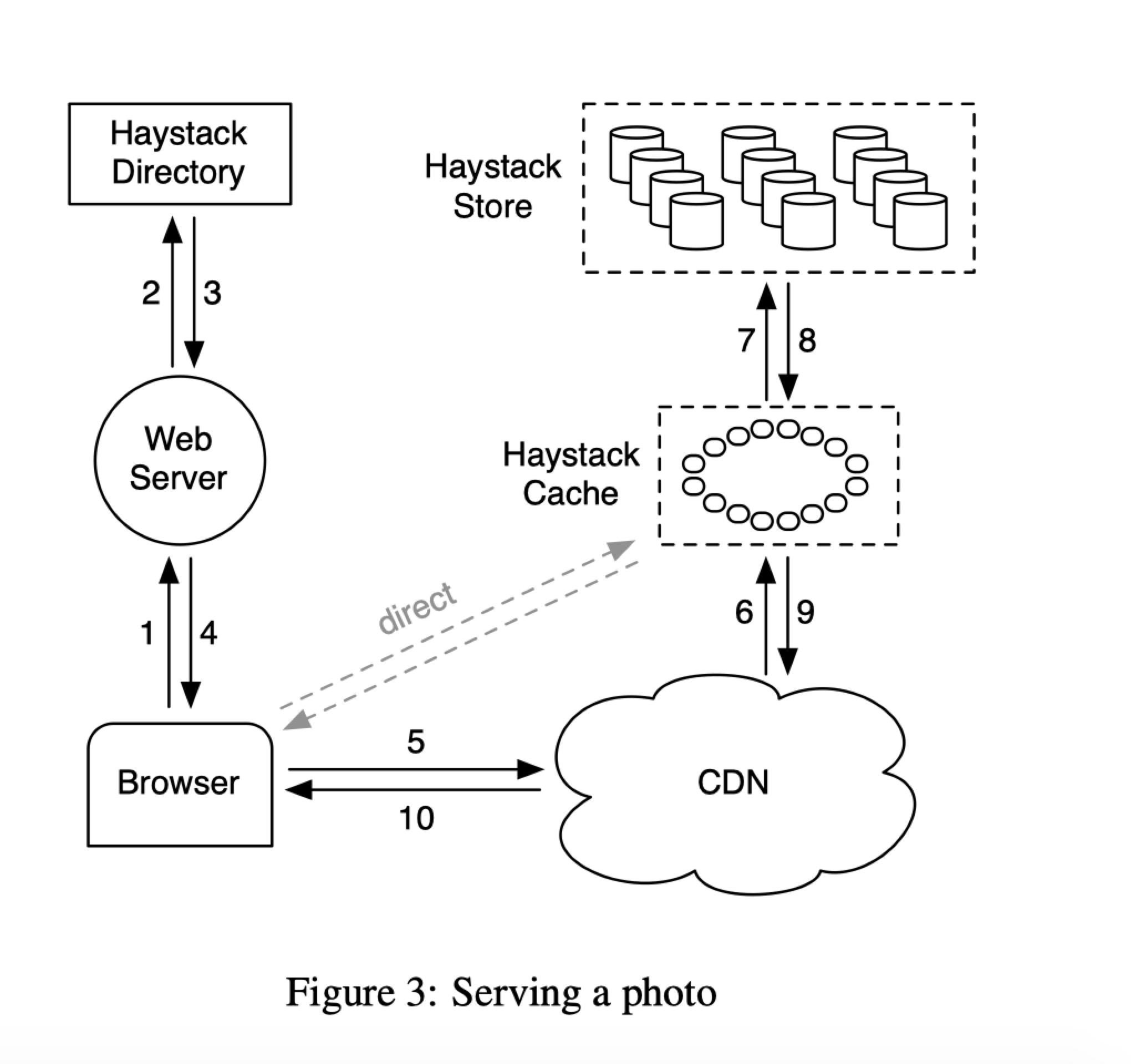
读流程(参考Figure 3),通过如下URL模式http ://CDN/Cache/MachineId/<LogicalVolume,PhotoID> 来访问图片。先访问CND, CND没有访问haystack cache, haystack cache没有就去机器上面找。
三, 数据存储
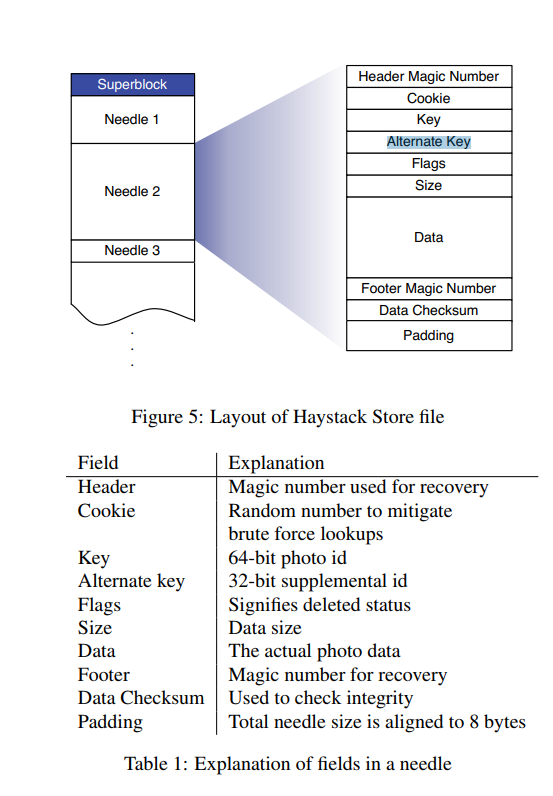
图片在haystack store上的存储格式使用日志文件系统的方式。开一Volume文件,将图片文件append到文件结尾, 记录该图片在这个文件的offset, 在内存中记录(id, alternative id) -> (volume offset, size)的映射。系统crash以后,可以使用volume文件来重建这个内存映射。读取时,从内存中获取图片的在volume文件中的offset, 一次I/O即可;删除文件时,将内存映射中该图片状态置为删除,同时更新volume文件中该图片的状态位。
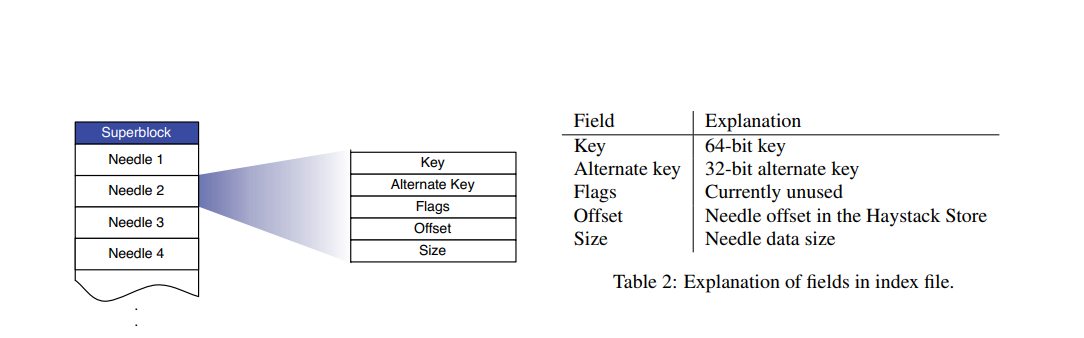
系统crash以后,重启首先需要重建内存映射。volume文件通常很大, 使得重建的过程太长;为了解决这个问题, haystack store上面维护一个索引文件(index file),每个volume文件都有一个索引文件,索引文件可以看做是内存映射关系的checkpoint。 图片在索引文件和volume文件中出现的相对顺序是一致的。索引文件异步更新,即, 把图片写入到volume文件的同时,并不会更新索引文件,索引文件的更新通过一个后台任务来完成。异步更新的好处是降低了写入时的延迟,还是一次I/O,坏处是引入了索引和数据可能不一致的风险。例如, 图片写入了volume文件,但在更新索引文件之前,系统crash了。重启之后,volume文件中的某些图片就没有索引; 或者某些图片被删除了,但索引文件中还存在对应的记录。对于有图无索引的情况,系统在启动的时候,可以获取索引文件的最后一条记录的offset, 在volume文件中,从这个offset开始扫描,为遇到的每一个图片文件在索引文件中加入相应的记录,能这么做的基础是前面提到的__顺序一致__。对于有索引无图片的情况,当被删除图片被访问到时,更新该图在内存映射中的状态, 将其设置为删除状态即可,在下次重做checkpoint的时候,该文件便不会在索引文件中出现。
由于haystack store中volume文件中的图片是采用标记删除,需要回收被删除的文件所占用的空间。 haystack store通过一个叫做compaction来回收空间: 扫描原有的volume文件,将没有被删除的图片,和非重复的图片,拷贝到一个新的volume文件中,重建一个新的内存映射关系; 拷贝过程中,不阻塞读写操作,图片的读写发生在旧的volume文件上(read和append), 图片的删除同时发生在新旧volume文件上(不需要判断一个图片是否已经被拷贝走了,如果没有,则需要在旧的上面删除,在新的上面删除会失败,但是没有影响; 如果拷贝走了,需要同时删除)。在扫描到了旧volume文件的尾部时,阻塞新的写入操作,切换到新的volume文件和新的内存映射关系。
四,内存优化
由于只使用flag来标记是否删除,把这个flag从内存中拿掉,用offset=0来表示删除;把cookie(用于防止猜测图片url的攻击)从内存中拿掉,图片读取出来以后获取cookie,再来比较;两项优化可以节约20%的内存使用。最终haystack每个图片只占用40个字节,相比xfs每个inode占用536个字节,只有原来的十分之一。计算一下100G, 内存可以放25亿张图片的元数据!
五, haystack cache回填策略
社交网络中,图片一般在上传后很快会被访问到,且短期的访问频率很高,过一段时间,访问频率又降下来; 文件系统在只有读或者只有写的时候, 性能相比同时有读写的性能要好。因此,新写到物理卷上的图片,会被回填到haystack cache, 这样可写的物理卷上面的读就大大降低了。haystack cache于是屏蔽在可写物理卷上面的读操作, 使得性能最优化。如果读请求来自CDN, 就不回填了, 因为CDN不命中的,会回填到CDN, 下次访问就命中CDN, 不需要访问haystack cache了。
六, 容灾机制
容灾做法比较简单,起个后台任务扫描,检查haystack store是不是可达,volume文件在不在,尝试读取数据;如果有问题了,把volume 文件置为只读状态。离线修复,迁移数据。
七,感受
haystack的架构非常简单实用,易于开发,容易短期投入获得立竿见影的效果。haystack的作者抓住了问题的主要矛盾,通过减少图片文件的元数据的大小,使得所有的元数据存放到内存中成为可能,从而减少每次图片访问IO的次数,降低延时,提高吞吐。容灾方案也是采用了非常简单的多副本写+RAID。数据的存储采用类日志文件系统的做法,通过append写+GC的方式, 降低写延时,回收空间。各种非常经典的做法,融合到一起,搭建了一个简单,实用的系统,值得学习。