问题描述
最近在把某业务的redis服务切换成TRedis服务,第一步需要把新的TRedis实例设置为正在对外服务的原生Redis实例的slave,并且使用原生Redis的同步方式进行主从同步。 在做slave的过程中,我发现TRedis在加载完master发过来的rdb文件后,master会将与slave之间的链接断开。且只要TRedis加载rdb的时间超过一定长度,问题就必现。 生产环境中日志级别为NOTICE,除了slave上面的 “Lost Connection with Master”以外没有其他的信息,我们把日志级别设置为debug再来看:
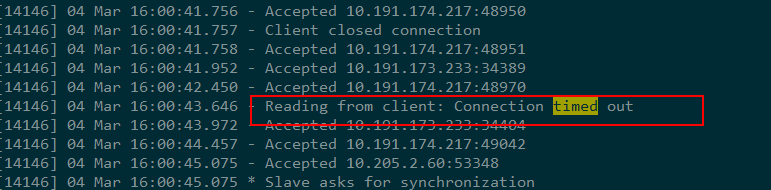
很明显了,就是master发现与slave连接的socket超时了, 将连接断开了。
代码逻辑
对于主从同步逻辑,我们比较熟悉,要点如下:
- 给slave发slaveof命令指定master的ip和port
- slave给master发sync命令
- master生成rdb文件,将rdb文件发送给slave
- slave接收rdb文件,加载到内存 或 rocksdb
- master将生成,传递rdb文件期间缓存的增量写请求发给slave
- slave将收到的rdb文件加载到内存或rocksdb后,开始处理5中slave发过来的增量写请求
从http://paralleld.github.io/redis/2015/11/02/reids-output-buffer-limit.html中,我们知道master把rdb发到slave后,立马就发增量写请求:
if (slave->repldboff == slave->repldbsize) {
close(slave->repldbfd);
slave->repldbfd = -1;
aeDeleteFileEvent(server.el,slave->fd,AE_WRITABLE);
slave->replstate = REDIS_REPL_ONLINE;
slave->repl_ack_time = server.unixtime;
// 新增的callback sendReplyToClient 负责将数据发送到slave
if (aeCreateFileEvent(server.el, slave->fd, AE_WRITABLE,
sendReplyToClient, slave) == AE_ERR) {
redisLog(REDIS_WARNING,"Unable to register writable event for slave bulk transfer: %s", strerror(errno));
freeClient(slave);
return;
}
refreshGoodSlavesCount();
redisLog(REDIS_NOTICE,"Synchronization with slave succeeded");
}
虽然给slave->fd这个socket加上了回调,但是数据能否发到slave那边取决于
- slave->fd在master上的写缓冲区是否有空间
- slave->fd在对端即slave上的读缓冲区是否有空间
- slave->fd在slave上的读缓冲区是否有空间取决于slave是否能把数据读到应用缓冲区
3就是问题的症结所在了,我们看代码:
/* Check if the transfer is now complete */
if (server.repl_transfer_read == server.repl_transfer_size) {
if (rename(server.repl_transfer_tmpfile,server.rdb_filename) == -1) {
redisLog(REDIS_WARNING,"Failed trying to rename the temp DB into dump.rdb in MASTER <-> SLAVE synchronization: %s", strerror(errno));
replicationAbortSyncTransfer();
return;
}
redisLog(REDIS_NOTICE, "MASTER <-> SLAVE sync: Flushing old data");
signalFlushedDb(-1);
emptyDb(replicationEmptyDbCallback);
/* Before loading the DB into memory we need to delete the readable
* handler, otherwise it will get called recursively since
* rdbLoad() will call the event loop to process events from time to
* time for non blocking loading. */
aeDeleteFileEvent(server.el,server.repl_transfer_s,AE_READABLE);
redisLog(REDIS_NOTICE, "MASTER <-> SLAVE sync: Loading DB in memory");
if (rdbLoad(server.rdb_filename) != REDIS_OK) {
redisLog(REDIS_WARNING,"Failed trying to load the MASTER synchronization DB from disk");
replicationAbortSyncTransfer();
return;
}
/* Final setup of the connected slave <- master link */
zfree(server.repl_transfer_tmpfile);
close(server.repl_transfer_fd);
// 把rdb加载完成后,才为slave<-->master的链接注册回调函数,
// createClient中会为server.repl_transfer_s注册一个readQueryFromClient的会掉,
// 负责把数据从读缓冲区读到应用层
server.master = createClient(server.repl_transfer_s);
server.master->rc_flag = REDIS_CLIENT_TRANS_SLAVE;
server.master->flags |= REDIS_MASTER;
server.master->authenticated = 1;
server.repl_state = REDIS_REPL_CONNECTED;
server.master->reploff = server.repl_master_initial_offset;
memcpy(server.master->replrunid, server.repl_master_runid,
sizeof(server.repl_master_runid));
/* If master offset is set to -1, this master is old and is not
* PSYNC capable, so we flag it accordingly. */
if (server.master->reploff == -1)
server.master->flags |= REDIS_PRE_PSYNC;
redisLog(REDIS_NOTICE, "MASTER <-> SLAVE sync: Finished with success");
......
}
可以看到slave在把rdb加载到内存以后,才会去处理master发过来的增量写请求。 前面说到,当master把rdb文件发给slave以后,马上发送增量写请求,其中一部分数据把slave端的读缓冲区占满了,另外一部分没法被slave接受,这个时候master端无法收到ack,就不停重发,直到重试tcp_retries2次,就关闭连接,返回etimedout错误。
证据
master向slave不断重发1448个字节的数据15次:

且第一次发送的时间和slave加载完rdb的时间一致: 15:44:46
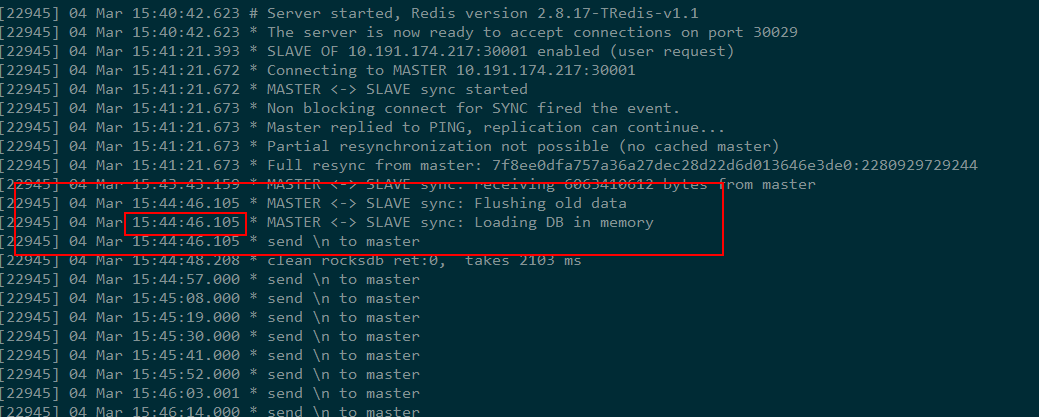
注意,master日志中返回Connection timed out的时间是:
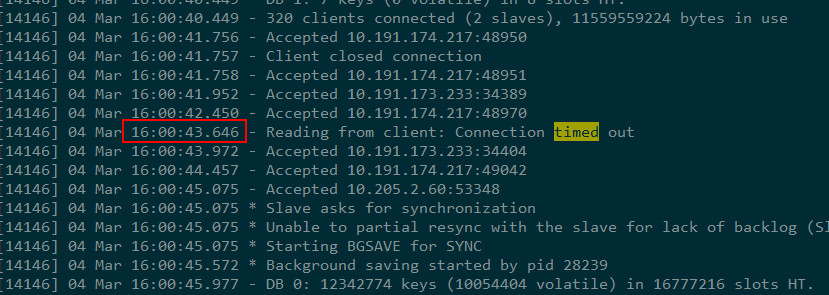
第五次重试后2分钟。 bingo。
解决方案
问题的根源清楚了,就是slave读缓冲区满了, 导致master发出的一部分数据没法被接受,master收不到ack,master在重试一段时间后,认为连接断掉了,就将socket关闭。而我们需要master一直重试直到把这部分数据发送成功。最简单和直接的办法是修改tcp_retries2参数,增加重试的次数。改到20, rdb加载完成后,master还在重试, 此时slave可以从缓冲区读出来。
思考
如果在使用redis的主从同步过程中,发生无法成功,无论如何调整client-output-buffer-limit和repl-timeout都不行的时候,需要考虑这种场景。个人认为这个是redis的设计缺陷。但是一般情况下都不会遇到这个问题,只有在load rdb时间超过900秒的时候才会触发这个问题。